저희 회사는 기존 Legacy 방식의 SIEM을 지속 사용중이었으나 다양한 부분에서 불편함과 업무 효율성이 떨어져 개선 방안을 고민하던중 Elasticsearch 플랫폼을 이용하여 기존 SIEM의 한계점을 극복하기로 하였는데요. 지금부터 Elasticsearch 스택을 구성하면서 겪었던 문제점들과 해결 방법에 대한 경험을 소개해드리도록 하겠습니다.
만약, 현재 팀내에서 대용량 SIEM 구축에 대한 고민을 하고 계신다면 이 글이 도움이 될것입니다. 개발 과정을 요약한 내용인데요. 서비스 형태나 로그량등에 따라 다르게 구성해도 됩니다. 본문의 내용은 제가 실제 Production 환경의 로그 데이터를 기반으로 POC를 진행했으며, ELK 스택의 8.x대 버전을 사용하였습니다.
- Logstash: 총 3대, 각 서버에 CPU 8 Core와 메모리 16GB를 할당
- Elasticsearch Master Node: 총 3대, 서버당 CPU 8 Core, 메모리 16GB
- Elasticsearch Data Node: 총 6대, 각 서버에 CPU 18 Core, 메모리 64GB(Heap 32G)
- 총 저장공간은 Usable SSD 18TB
Elasticsearch 구축시 문제점 발생(트러블 슈팅 내용)
운영 초반, 아래와 같은 몇 가지 심각한 문제가 발생하여 적지 않은 어려움을 겪었습니다. 하지만, 이와 같은 상황외에도 다양한 부분에서 시행착오를 겪을 각오를 해야합니다. 해결 방안은 분명히 있으니 너무 두려워 마시기 바랍니다. ^^
- Kibana 대시보드에서 시각화 작업을 수행할 때, 쿼리 기간이 길어질 경우(예: 24시간) Data Node에서 OOM(Out of Memory) 오류가 발생
- Data Node에서 검색 기간이 길어지면 GC 오버헤드 발생
- 그 외 소소한 운영 이슈 몇 가지
문제 해결 방향과 진행했던 튜닝 포인트
위 문제들을 최적화하기 위해 다각도로 조사를 진행한 결과, 다음과 같은 해결책 및 튜닝 방안을 도출했습니다.
- 메모리 설정 최적화: 특히 Data Node를 중심으로 힙 메모리(heap memory) 크기를 포함한 적절한 메모리 할당
- OS 레벨의 대용량 처리 튜닝: sysctl 커널 파라미터 조정을 통해 데이터 처리 성능 개선
- Shard 수량 조정: Shard 개수는 무턱대고 증가시키지 말고, 필요 최소한으로 관리하여 자원 낭비 방지
- Index Buffer 설정 최적화: indices.memory.index_buffer_size 값을 조정하여 인덱스 처리 성능 향상
- Thread Pool 조정: thread_pool.search.queue_size 및 thread_pool.bulk.queue_size 값을 적절히 설정
- _all 필드 비활성화: 기본적으로 6.0 버전부터 비활성화되지만 "_all": {"enabled": false}를 명시적으로 설정
- Refresh Interval 조정: 불필요한 리소스를 줄이기 위해 "refresh_interval": "30s"로 설정
- 리플리카 최적화: 서비스 상황에 따라 "number_of_replicas": "0"로 설정
- Kibana Index Patterns 정리: 불필요한 데이터 처리를 줄이기 위해 Source Filter를 34개 적용
- Field Data 제한: indices.breaker.fielddata.limit 및 indices.fielddata.cache.size를 활용해 메모리 사용 제어
DATA Node 확장 및 최적화 방안
위와 같은 튜닝 작업 이후에도 근본적인 문제 해결을 위해 Data Node 확장을 통한 메모리 사용 분산이 가장 현실적이고 효과적인 대안이라는 것을 확인했습니다.
추가적으로 실제 Production 환경에서는 서비스 특성과 목적에 맞는 추가적인 최적화 전략이 필요합니다. 예컨대, 데이터 인덱싱 처리량이 많고 데이터를 장기적으로 보유해야 한다면 Hot-Warm 아키텍처를 사용하는 것을 고려할 수 있습니다. 또한 대규모 이벤트 데이터를 처리하는 경우에는 Logstash 앞단에 Kafka를 구성하여 데이터 구조를 보다 효율적으로 관리할 수도 있습니다.
결론적으로 ELK 스택의 최적화 방법은 서비스의 운영 목적(예: 검색 위주 운영 또는 단순 데이터 저장소 기능)에 따라 매우 다르게 접근해야 합니다. 상황에 맞는 세밀한 전략 수립과 지속적인 모니터링이 중요합니다.
개발 결과 요약
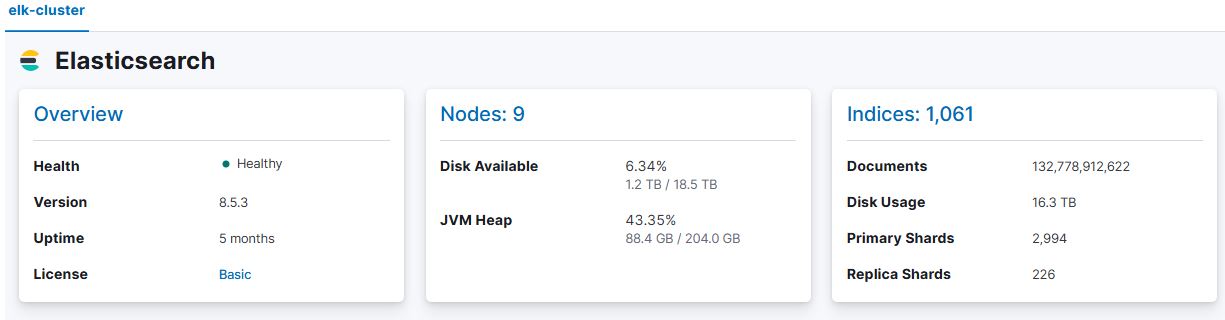
1. 클러스터 상태 확인
Elasticsearch 클러스터 상태는 다음 명령어로 확인 curl http://x.x.x.x:9200/_cat/health?v
2. 보안 이벤트 처리 규모
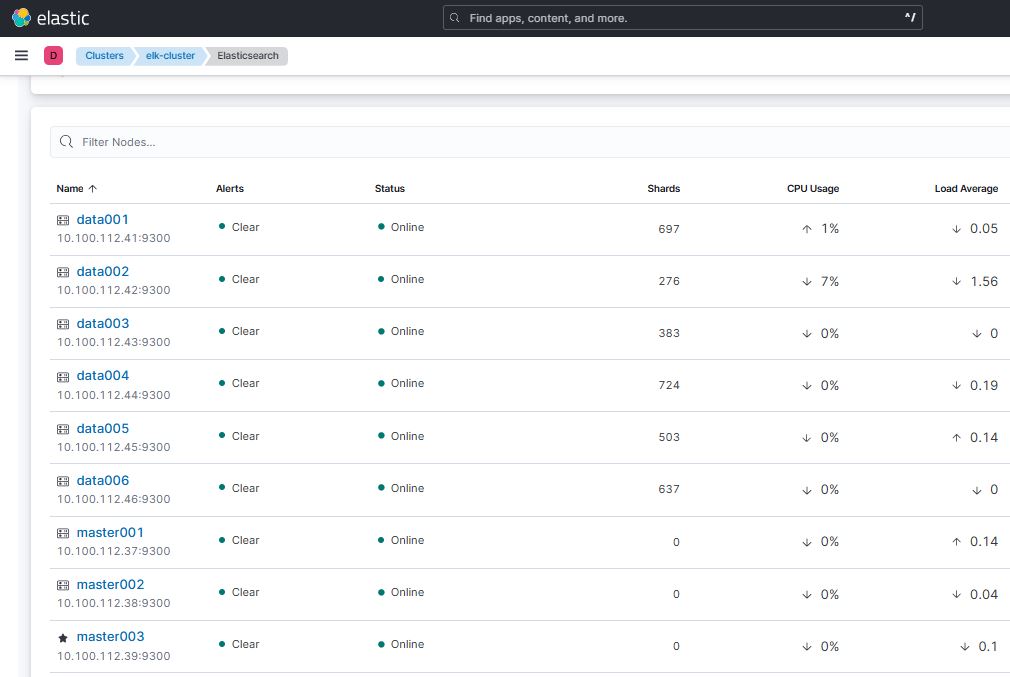
- 1시간 평균 보안 이벤트 발생량: 약 3000만 건
- 1일 기준 보안 이벤트 발생량: 평일 평균 약 7억 ~ 10억건
3. 네트워크 트래픽 상태
- IN/OUT 트래픽 처리량: 초당 약 100~120MB 수준
4. 스토리지 데이터 사용량
- 하루 평균 저장되는 데이터 용량: 약 100GB~110GB 정도 (데이터는 ArcSight에서 CEF 포맷으로 전처리되어 ELK 스택으로 전송되며, 이 과정에서 CEF 포맷 파싱 때문에 저장 용량이 증가함)
5. ELK 스택 클러스터 구성 운영 현황
현재 구성으로 ELK 스택이 정상 운영됨
- LogStash: 총 3대 운영
- Master Node: 총 3대
- Data Node: 총 6대
6. 확장 및 최적화 고려 사항
실제 프로덕션 환경에서는 클러스터의 성능 요구 사항에 따라 노드를 추가하거나, 각 노드별 컴퓨팅 자원을 증대시키는 방안을 반드시 검토해야 합니다. 지금까지 설명드린 Elastic 구성은 현재 안정적인 시스템 운영을 지원하지만, 보안 이벤트나 네트워크 트래픽의 증가에 대비해 유연한 확장을 위한 계획이 필요합니다. 스토리지 사용량 또한 CEF 포맷으로 인해 예상치 못한 증가가 발생할 수 있으므로 지속적인 모니터링 및 관리가 필요합니다.
요즘 트렌드를 보면 빅데이터라는 단어와 온갖 용어가 결합되어 인터넷이나 기사에서 마케팅 용어로 과도하게 사용되고 있는 것이 눈에 띕니다. 정보 보안 분야에서도 몇 년 전부터 빅데이터라는 수식어가 계속해서 붙기 시작했고, 이제는 빅데이터 기반 차세대 SIEM, 빅데이터를 통한 보안 강화, 빅데이터 보안 분석 솔루션 등 다채로운 표현들이 넘쳐나고 있습니다.
이러한 표현들은 분명 좋은 의도를 담고 있고 긍정적인 방향성을 가지고 있습니다. 그러나 문제는 이름만 번지르르하게 갖다 붙이는 것으로는 충분하지 않다는 데 있습니다. 비용을 들여 상용 제품을 운영하거나, 자체적으로 솔루션을 개발해 운용하더라도 결국 빅데이터는 제대로 활용되어야만 의미가 있습니다. 빅데이터를 통해 가치 있는 정보를 창출하고, 이를 통해 업무나 기업 차원에서 실질적인 이점을 만들어내야만 투자 대비 성과를 기대할 수 있습니다. 안타깝게도 현실에서는 대규모 예산을 투입하고 인력을 배치했음에도 기대만큼의 효과를 얻지 못하는 사례가 적지 않습니다.
특히 정보 보안 업무에서 빅데이터를 접목하려 한다면 몇 가지 핵심 요소가 선결되어야 합니다. 우선 빅데이터를 관리하고 분석할 수 있는 전문 인력이 반드시 필요하며, 관련된 업무 프로세스가 명확히 정립되어야 합니다. 또한, 현재의 업무 흐름이 이 기술로 인해 개선되고 더 큰 가치를 창출할 수 있는지가 중요합니다. 단순히 기술을 도입하는 것으로 끝나는 것이 아니라, 실제로 업무와 기업에 긍정적인 변화를 가져와야 의미가 있을 것입니다.
어떤 IT 언론 기사의 말을 인용하자면, 하루 수천에서 수억 건의 보안 이벤트가 발생하지만, 이 중에서 진짜로 중요한 위협으로 간주되는 데이터는 1~2%에 불과하다는 이야기가 있더군요. 이런 극소량의 데이터를 정확히 찾아내기 위해서는 어마어마한 노력과 프로세스가 필요합니다. 요즘에는 AI와 머신러닝 기반의 보안 솔루션도 쏟아져 나오고 있지만, 몇몇 APT 보안 장비를 테스트해본 결과 여전히 사람의 손길이 필요하다는 것을 느꼈습니다. 오탐에 대한 필터링이라든지, 최종적인 판단 부분에서는 아직도 누군가의 지속적인 모니터링이 필수적입니다.
결국 빅데이터, AI, 머신러닝과 같은 기술이 발전하면서 IT 종사자라면 이를 무작정 부정적으로 바라보기보다는 기술을 분석하고 도입 가능성을 진지하게 검토하는 태도가 필요합니다. 새로운 기술을 도입할 때는 단순히 트렌드에 휩쓸리지 말고, 과연 이 기술이 업무에 효율적일지, 현재 체계를 얼마나 개선할 수 있을지, 나아가 기업 및 서비스 관점에서 실질적인 이익을 가져올 수 있을지를 깊이 고민해야 합니다. 이러한 과정 없이는 제대로 된 투자의 성과를 기대하기 어렵습니다. 충분한 고민과 철저한 검토가 있을 때 비로소 투자 대비 최대의 효과를 거둘 수 있을 것입니다.
'AI, IT 이야기' 카테고리의 다른 글
| Elasticsearch Lucene Query 사용 사례 - 1편 (1) | 2025.06.10 |
|---|---|
| Elktail CLI 기반 Elasticsearch 쿼리 조회 팁 (0) | 2025.06.04 |
| Arcsight & Elastic Stack 통합 SIEM 구축 사례 (0) | 2025.05.30 |
| 대용량 전처리 Logstash Filter 이렇게 사용해보세요 (0) | 2025.05.28 |
| 보안운영의 미래 SECOPS 도입 사례 (0) | 2025.05.21 |



